Qwen能吞下整本扫描版PDF,直接转Word了,这波操作太赞了!
经常收到读者后台留言,问如何处理扫描版PDF,怎么把里面的字准确批量提取出来,然后保存为txt,word啥的。
今天这篇文章我来探索一种较好的解决方案,提供完整智能体源码,详细操作步骤,确保大家可以复现,感兴趣的可以看看。
1 展示效果
从我电脑上找了一本《天池比赛》扫描版PDF,扫描版意思就是全是图片,并且图片清晰度不怎地。
下面是使用本文介绍的方法,批量处理这个扫描版PDF,选取第十页的提取结果,左侧图是原版,右侧是提取后保存成word的结果:

大家可以对一对,我看了下提取正确率非常高,所以想要处理扫描PDF的可以使用本文方法。
一句话总结下这个解决方案:基于 Qwen2.5-VL-7B 多模态大模型构建智能体,自动读取扫描版 PDF,借助图像多模态逐页理解内容,并按阅读顺序整理输出,最终生成结构清晰的 Word 文档。
这个方案的主要特色:
1)7B模型,消费级显卡完全可以本地运行;
2)基于多模态(Vision-Language)能力理解图片内容,相比传统的OCR识别方法,准确度大大提升;
3)全自动化批量处理,放在后台运行,一本书很快就能转化完。
有些读者跑这样的模型一回,电脑就热的发烫,心疼电脑。还有些电脑没有GPU,跑起来太慢了。
确实也是,在本地跑大模型很耗电脑,没有GPU效率也很慢,最好的方法就是薅一些平台的羊毛,他们提供了远程GPU算力,一般注册刚开始都会送一些券,够用一段时间。
比如腾讯云,gpugeek,阿里云,这些平台都提供了GPU算力,其中gpugeek的算力平时经常用,用起来挺友好,送的券现在还没用完。今天就以他家的这个平台,咱们把扫描版PDF直接转出word来,走起。
2 薅GPU算力
进入gpugeek,如下所示:
点击右上角登录,进入下面界面,选择创建实例:
选择一个型号,比如24GB显存跑Qwen2.5-VL-7B,足够了:
RTX-A5000, 24G显存,95GB内存:

选择官方镜像,依次选择如下图所示,Miniconda主要为了配置环境:
点击创建后,GPU算力镜像开始创建:

显示运行中,表明镜像创建好了,直接就能开始薅他家的GPU算力了:

然后点击登录:

复制登录指定到命令窗口:
输入密码后,登录到GPU服务器,如下图所示:
使用下面命令查看GPU:
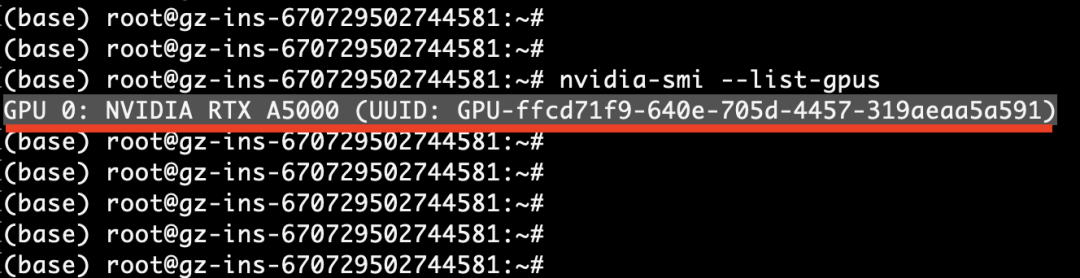
nvidia-smi --list-gpus
如下所示,显示为GPU 0,RTX A5000型号:
3 安装环境
安装torch,transformers等,直接复制下面两行命令执行:
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121pip install transformers safetensors
如果要处理视频或多模态任务,再安装opencv-python:
pip install opencv-python
再安装加速依赖包:
pip install accelerate
以上环境就安装好了,不需要写代码,只需要执行命令。
咱们搞个demo,大家直接复制下面代码,保存为:vl_ocr.py
然后输入如下命令运行,如下图所示:
因为本地还没有下载过"Qwen2.5-VL-7B" 模型,所以 transformers 框架自动去 Huggingface 下载模型的全部权重文件。model.safetensors.index.json 是模型的索引文件。model-00001-of-00005.safetensors 等这几个是模型的权重分片(大模型通常被切成多个小块,分片下载)。
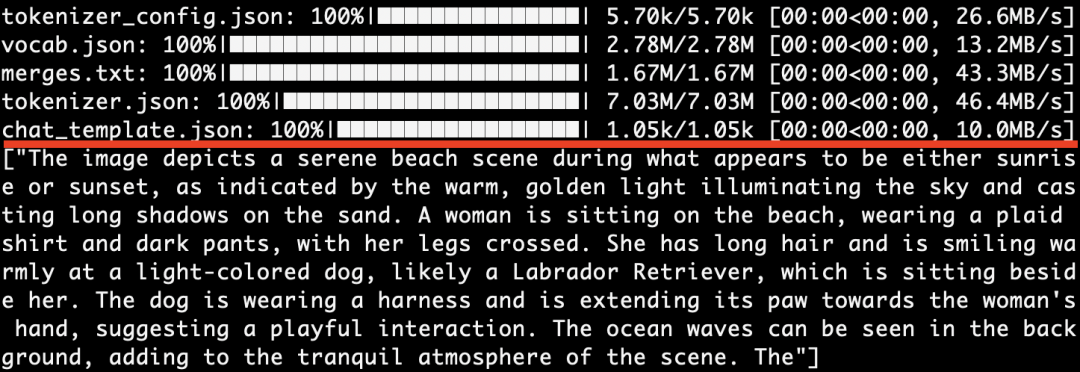
咱们默认输入如下这个图片,让它理解下这个图的信息:
![img]()![img]()
返回英文了:
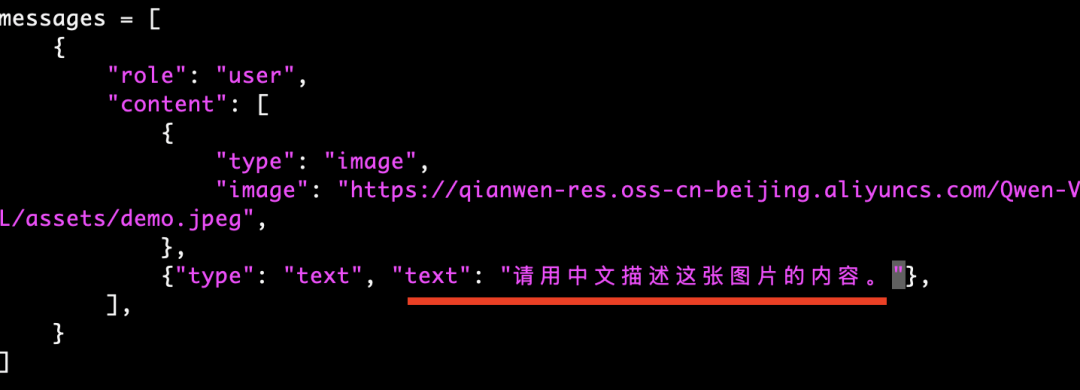
咱们修改下代码这里,提示词告诉它使用中文描述:
下面是中文返回结果,如下图所示:
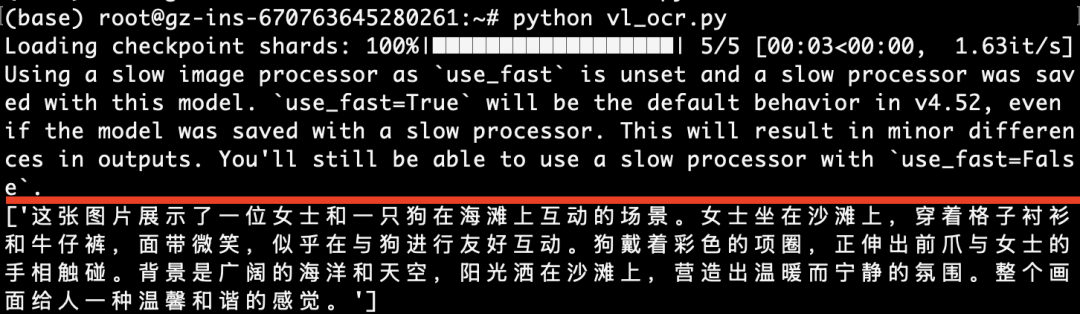
以上描述结果,大家觉得如何,有没有觉得很精准呀。
4 扫描版PDF开始转Word
上传一个300多页的pdf文件到服务器,使用scp命令:
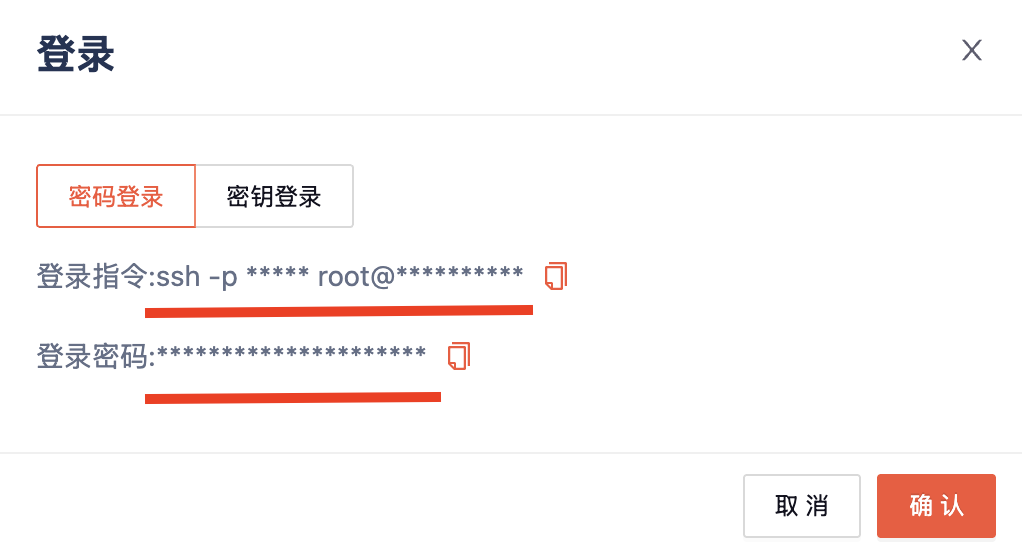
scp -P 41277 ocr_test.pdf root@你的服务器名字(来源文章一开始复制的登录地址)
提示输入密码后,输入文章一开始登录地方的密码,如下图所示:
![img]()![img]()
再安装PDF转Image的包:
pip install pdf2image python-docx
然后安装pdf2image的一个系统依赖包,如下所示:
sudo apt updatesudo apt install poppler-utils
完整代码scanpdf_to_doc.py文件一共89行代码,是的,只需要89行代码就可以实现这样的实用功能:
程序运行后的效果如下图所示:
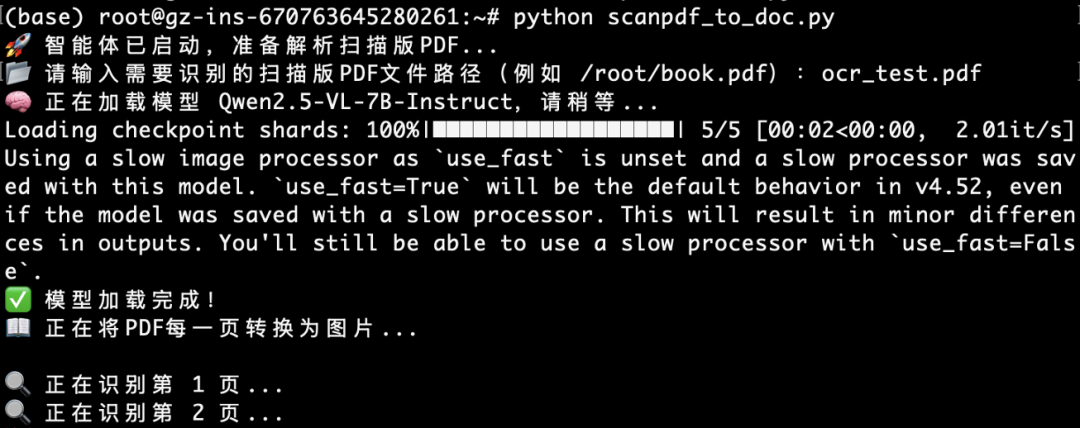
特意找了难度最高的目录页,因为目录页清晰度很差,但是展示效果如下图所示,没有问题,就连页码也都对齐整了:

限于本文篇幅,以上完整89行源代码文件全部放在下面我的公众号,获取方式回复:智能体

以上就是扫描版PDF转word的完整步骤,所有代码也全部为大家准备好,大家只需实践下就行。
以上方法也不是完美的,我看了下,目前发现只有目录部分转化有些问题,因为目录分为左右两个部分,但是转Word后,只把左侧目录完整转出来了,右侧部分有些丢了未转化,同样方法问了更满血的国外模型也不行,相信未来多模态大模型能搞定。
最终总结
本文章解决了一个大家普遍遇到的问题,就是如何将扫描的PDF书直接转为word,文中介绍了基于 Qwen2.5-VL-7B 多模态大模型,自动读取扫描版 PDF,具有如下特色:
转化准确率高;哪怕一整本扫描的书也能轻松应对;文中全部代码和步骤都开源,确保大家可以复现。
关于跑Qwen2.5-VL-7B大模型使用算力问题,可以薅下gpugeek这家公司的羊毛,目前我看到他家注册还有多重福利,学生认证还能领到更高的券,感兴趣的点击下面【阅读原文】可以试试。海外版现在我看着也有了,访问地址:https://gaias.io
后面再有遇到扫描版PDF转Word的,大家记得回来看这篇教程。好了就到这里。
以上全文4