28 DeepSeekMine个人知识库软件三个使用技巧
咱们每个人电脑上都有很多文件,随着AI大模型技术发展,高效检索个人知识库,然后叫大模型帮我们分析,是一个高效提升工作效率的方法。
在过去二个月,我和一位小伙伴,一起攻坚克难,实现了上面的大模型接入个人知识库功能,又被称为RAG(Retrieval-Augmented Generation)。
为了好记忆,我们把软件命名为:DeepSeekMine.
这篇文章我将解答大家在使用DeepSeekMine-V6过程中普遍关心的一些问题,并且深入介绍软件背后的算法内核和技术原理,对这些感兴趣的可以看看。
1 DeepSeekMine使用技巧一
个人知识文档是有分类的,比如生活类,工作类,理财类,体育类,新闻,娱乐类等等。基于这个特点,我们在开发DeepSeekMine时,算法就考虑了此维度,加速大模型回答速度同时,还提升RAG精度。
在界面中表现如下,大家可以分门别类,创建多个分类卡片,如下一共创建了4类:
所以大家在使用DeepSeekMine时,非常建议大家新建这样多个卡片,分门别类上传自己的个人文件,这是第一个使用技巧。
2 DeepSeekMine使用技巧二
本地跑大模型还是比较消耗机器,再加上RAG功能,就会更加消耗电脑资源,其他知识库,如cherry, anythingllm等,回答延时就会比较长,我用过,有时一次回答延时竟有2分钟,所以我们设计DeepSeekMine时,就想解决此问题,到V6版本,配置DeepSeek-R1:1.5b回答,能做到1秒钟回复。
通过下面的GIF动画,大家可以验证下回复速度是不是这样,GIF无任何加速,全部保持原始速度。我的测试机器是m1-pro, 16G内存,没有GPU显卡。限于公众号内帧数限制,只能截取前几帧:
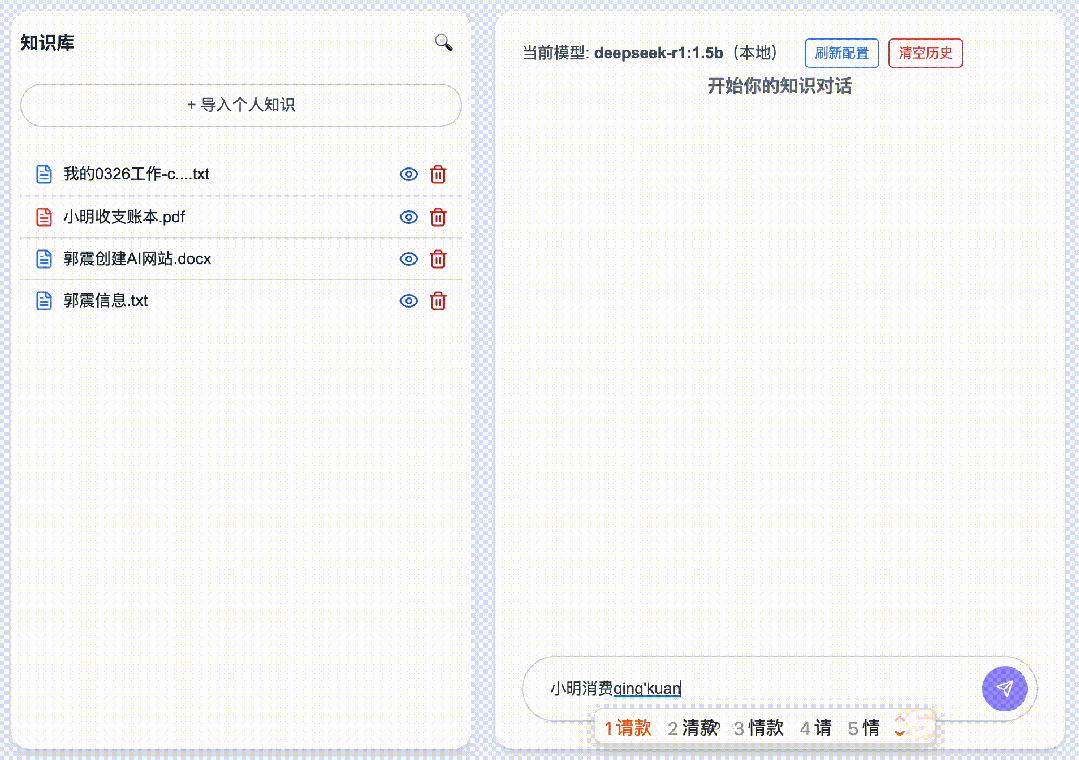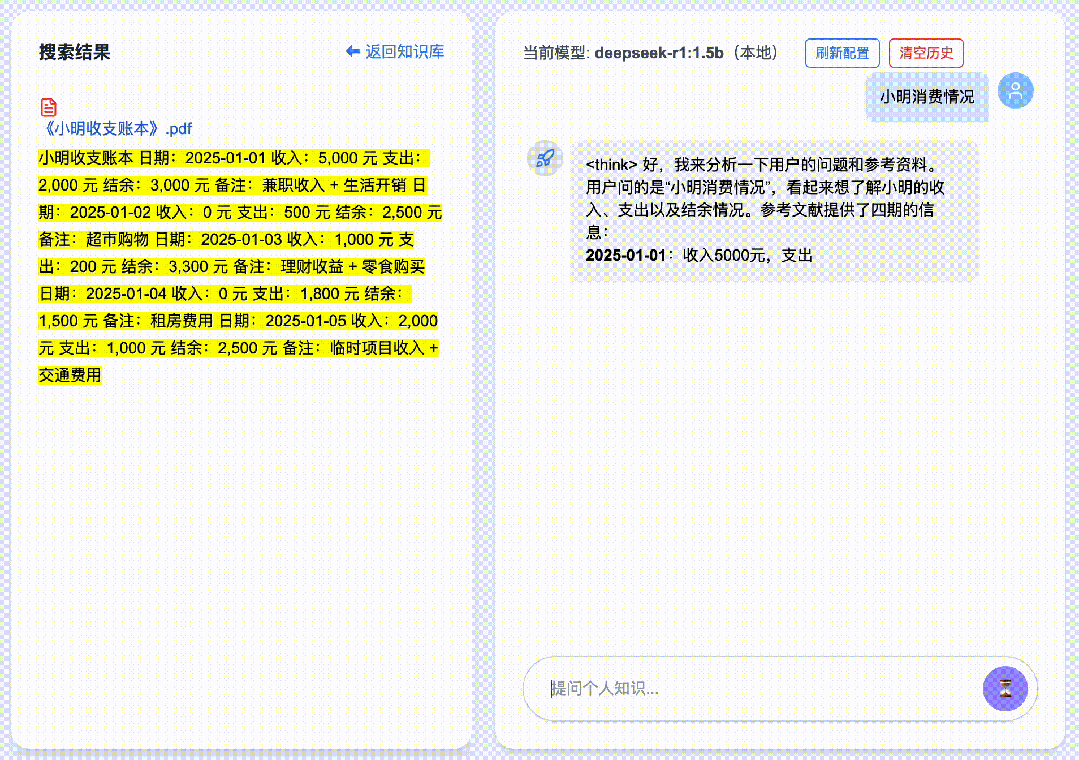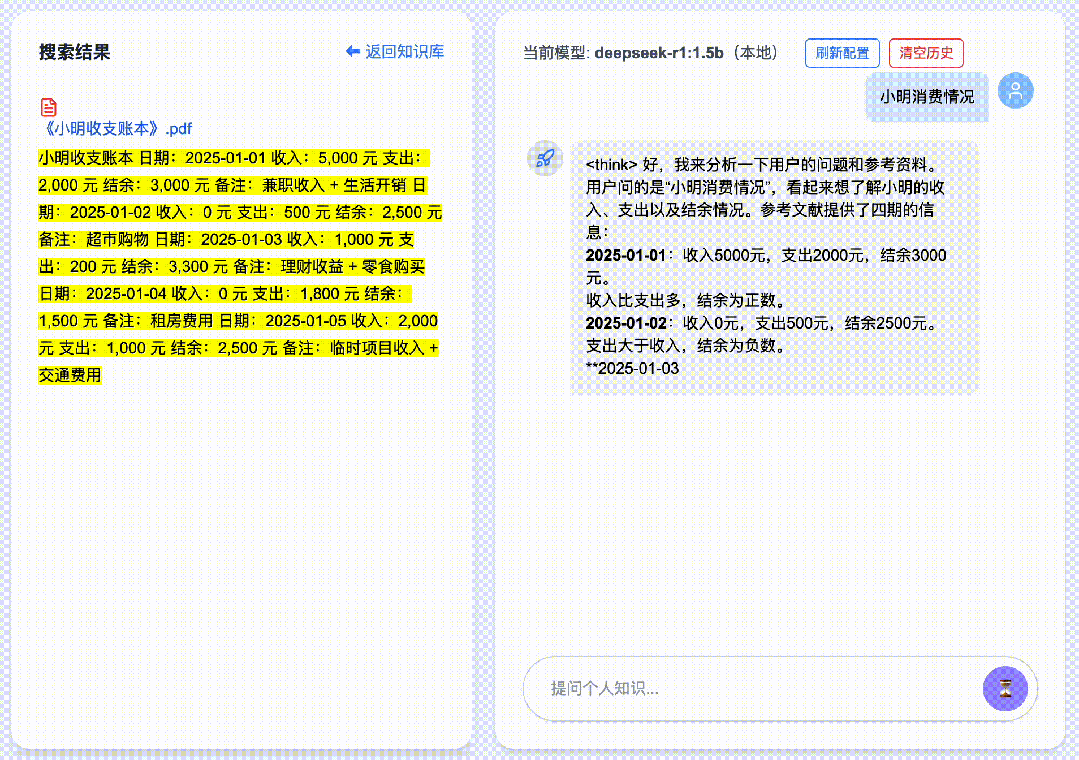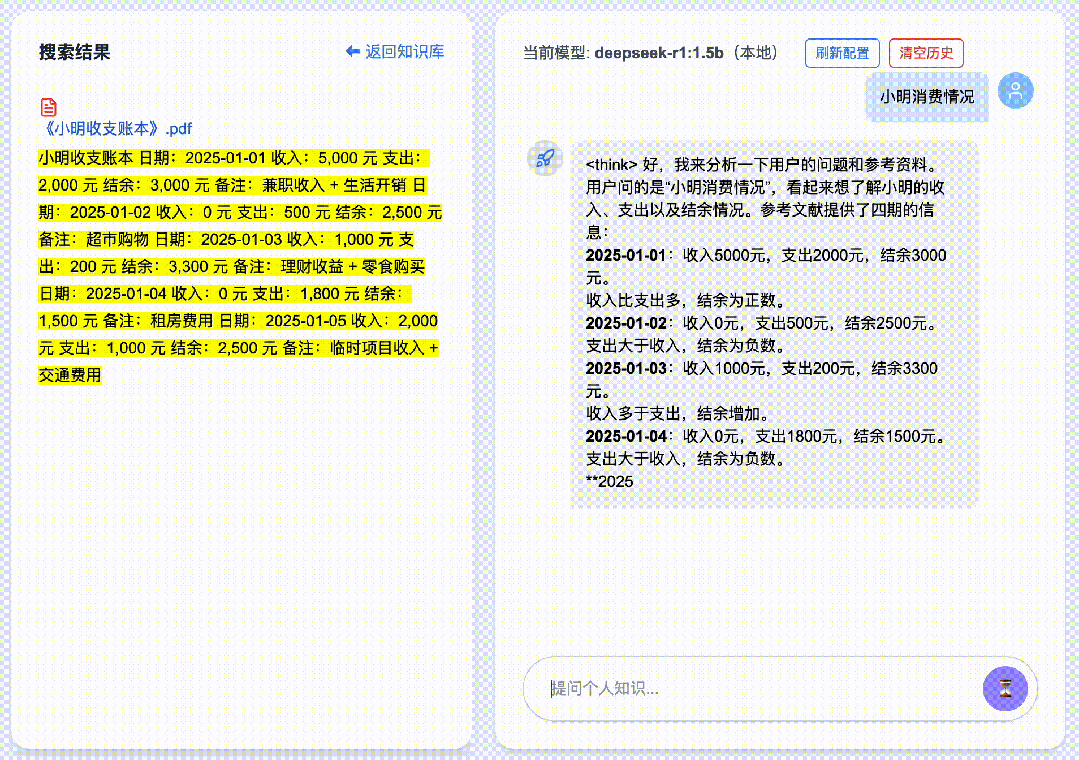
如何做到在本地算力下秒级回复的,DeepSeekMine算法是混合RAG算法,利用关键词检索和语义向量结合,高效做到RAG响应。设计的混合RAG算法,从业务角度看,算法主线有两条,文档上传处理,用户查询处理。
文档上传处理的算法流程如下图所示,包括用户上传单个或多个文件 → 知识库文件智能分类 → 后台多线程并发处理 → 线程1/线程2/线程3/线程N → 智能文档切片 → 中文文档进行分词 → 去除停用词 → 微服务异步计算嵌入向量 → 写入Meilisearch:
用户查询处理的算法流程如下所示,包括用户输入查询问题 → 中文查询进行分词 → 计算查询嵌入向量 → 领域语义匹配 → 关键词两轮筛选+BM25算法 → 查询与向量关系矩阵优化算法 → 定制rerank算法:
所以基于以上算法设计,大家在使用DeepSeekMine时,提问的问题中尽量包括一些准确的关键词,然后组合起来提问它,这是第二个使用技巧。
举个例子,比如这样提问:Janus-Pro能做什么事情,Janus-Pro就是最重要的一个关键词,大家看看下面的回复,哪怕使用1.5b这样的小模型,回答总结的都很精准,如果配置更好的模型,那就彻底起飞了:
3 DeepSeekMine使用技巧三
一次会话包括多轮用户和助手的来回交流,DeepSeekMine会把历史交流和命中的知识库文档一起注入到大模型,然后让大模型学习和总结,这里利用了大模型的few-shots learner特性。
但是很多大模型应用这样设计都会有一个问题,如果某次或某些会话它回答的不够精准,就会干扰接下来的回答质量。
基于此,一旦中间回答出现漂移问题,可以点击「清空历史」按键,重新开始提问,这是第三个使用技巧:
为了大幅减少漂移问题,DeepSeekMine软件也提供了不同大模型配置功能,这也是大家普遍关心的一个问题,在这里详细介绍下。
比如ollama本地安装的不同大模型,只需要1.5b改为8b,自动将会启用8b做回答:
此外还支持云端API配置,如下所示配置也比较方便:
还未获取DeepSeekMine软件最新V6版本的,可以在下面公众号回复,知识库:

4 软件V7升级计划
接下来的 V7 版本升级大概计划如下:
1)将持续优化 RAG 算法内核,进一步提升精确率(Precision)与召回率(Recall),这两个核心性能指标,全面增强检索与生成的准确性。
2)计划给大家接入更多强劲的大模型,受限于算力等困难,有些大模型不大可能直接在本地部署。
比如,DeepSeek-R1满血版,参数671B,FP16跑至少上百张GPU显卡,搭建费用高达几百万,即便量化版也得需要不菲的成本,所以对于个人而言,成本太高了。
还有一些闭源模型,通过走API调用,帮助大家更加精准的做RAG.
3)界面 UI 持续优化,一直是我们努力的方向,力求为大家带来更流畅、更舒适的使用体验。
例如在主界面中,我们将新增三栏面板的显示与隐藏功能,支持响应式布局,自由切换视图:
4)另外,更多大家普遍关心想要增加的功能,我们都会考虑,排期开发。
5 最后总结一下
本篇文章主要介绍了DeepSeekMine软件使用,三个技巧,大模型配置,V7开发计划。
三个使用技巧分别为:
1)文档分类上传,可提升检索效率与回答精准度;
2)通过混合 RAG 算法,实现资源受限条件下的秒级响应;
3)支持多轮对话记忆管理与模型灵活切换。
最后预告了 V7 版本将继续优化 RAG 精度、引入更强模型,并持续打磨 UI 和体验。