English translation
I Tested Qwen3.7-Max Against Claude Opus 4.8 and DeepSeek-V4. The Result Surprised Me.
Hi, I am Guozhen.
Recently, two new models were released: Qwen3.7-Max and Claude Opus 4.8.
On the benchmark list I was watching, Claude Opus 4.8 ranked first.
Qwen3.7-Max ranked second, with only Opus 4.8 ahead of it.
But how do they perform in real production tasks? I spent the last two days testing them. Here is what I found.
1. The new model context
This is the Code Arena WebDev leaderboard. Opus 4.8 and Qwen3.7-Max are the top two:
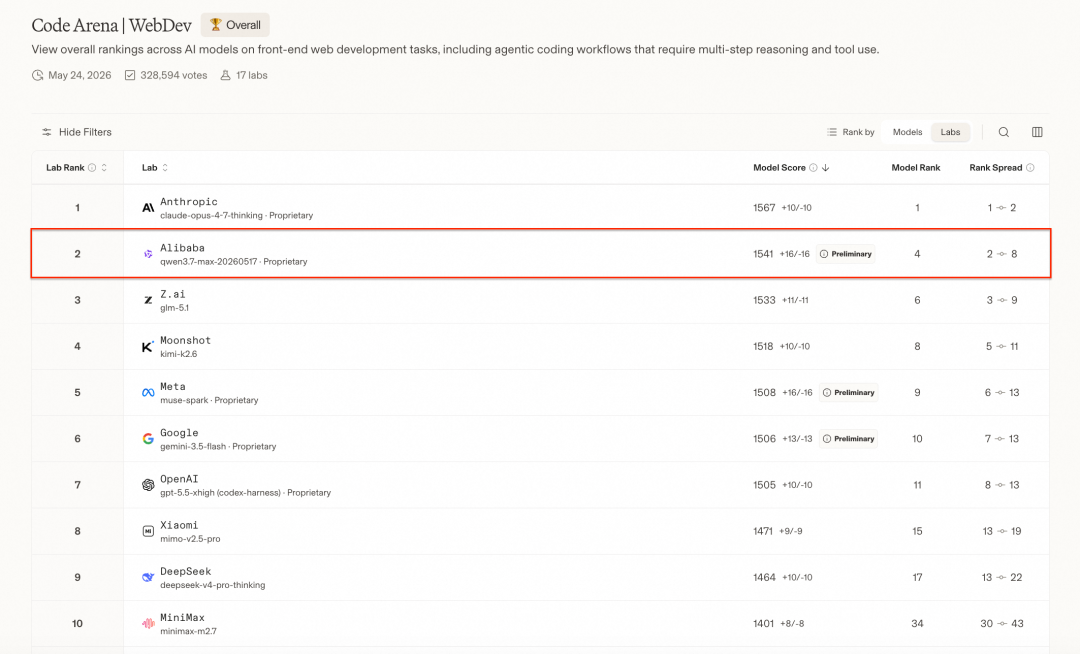
This leaderboard evaluates how AI models perform on page implementation, complex interaction, multi-step coding, tool use, and related web-development tasks.
One thing worth noticing: Zhipu, Kimi, Xiaomi, DeepSeek, and MiniMax all appear on the list. Chinese large models are clearly becoming more competitive.
I consider this leaderboard useful because it is close to real development work.
So I went straight into a hands-on test.
2. Side-by-side test
The test idea was simple: use a typical small-to-mid-size agent task and evaluate a capability many people care about.
Then I used Gemini-3.5-Flash and GPT-5.5 as judges. Their scores were used to make the evaluation more objective.
The agent task prompt was:
Develop a single-file HTML page that implements an Excel data analysis and visualization tool.
Support uploading .xlsx/.xls files. Use SheetJS to parse Excel files, read multiple sheets, and display searchable, paginated, horizontally scrollable data tables.
Automatically identify field types, count rows and columns, calculate missing values, unique values, max/min/average/sum, and generate a Chinese data-analysis report.
Use ECharts to automatically generate bar charts, line charts, pie charts, scatter charts, and other visualizations. Also allow users to choose X/Y fields and chart types to generate custom charts.
Only output complete runnable single-file HTML code. Do not explain. Do not use Markdown. Do not depend on a backend.
First, I sent it to Qwen3.7-Max:
I saved the output as an HTML file and opened it:

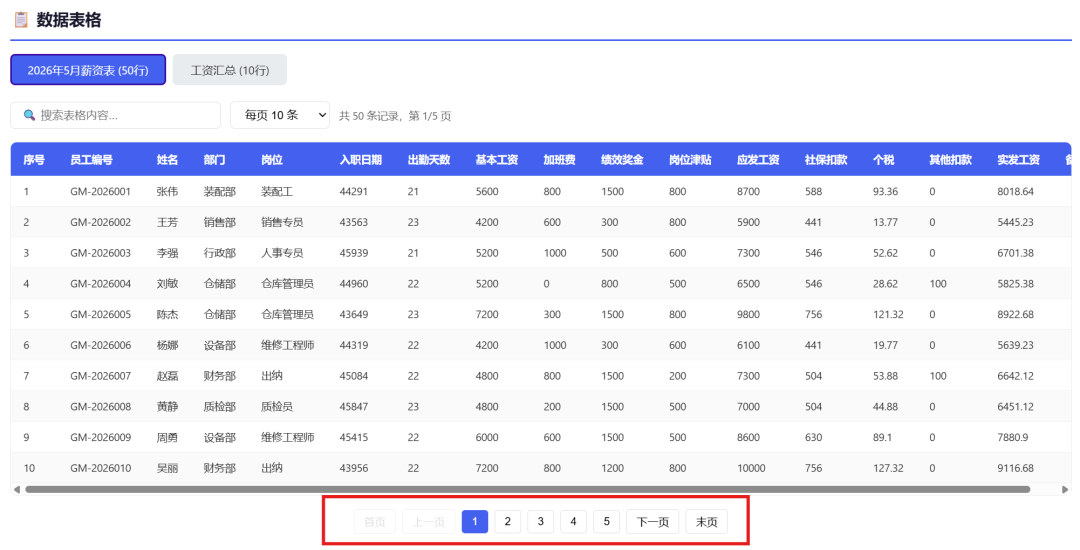
After importing an Excel file, it displayed the data with automatic pagination:
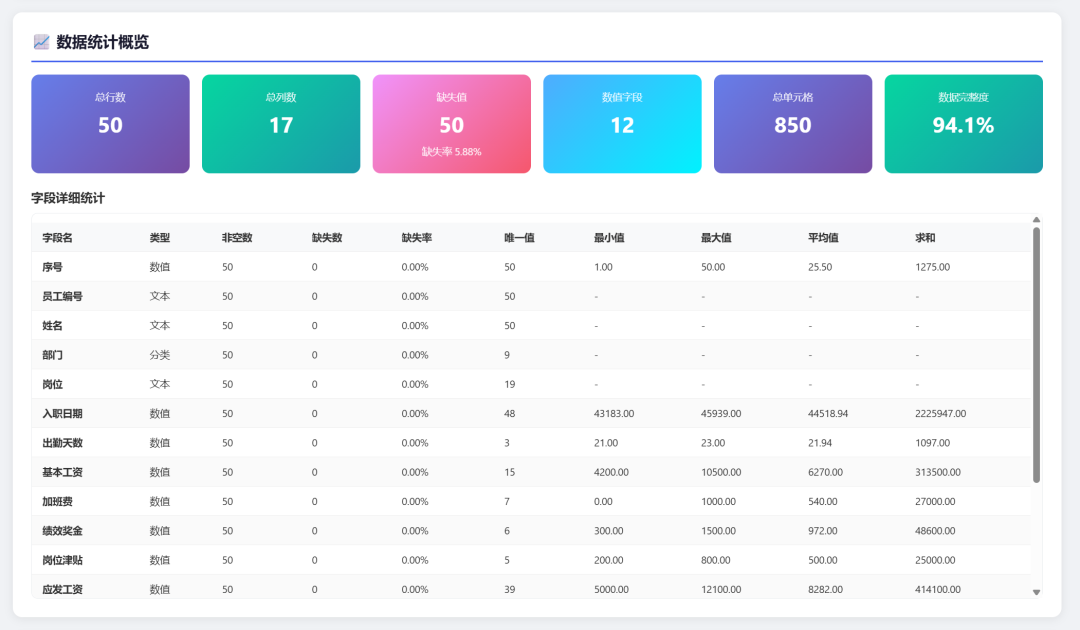
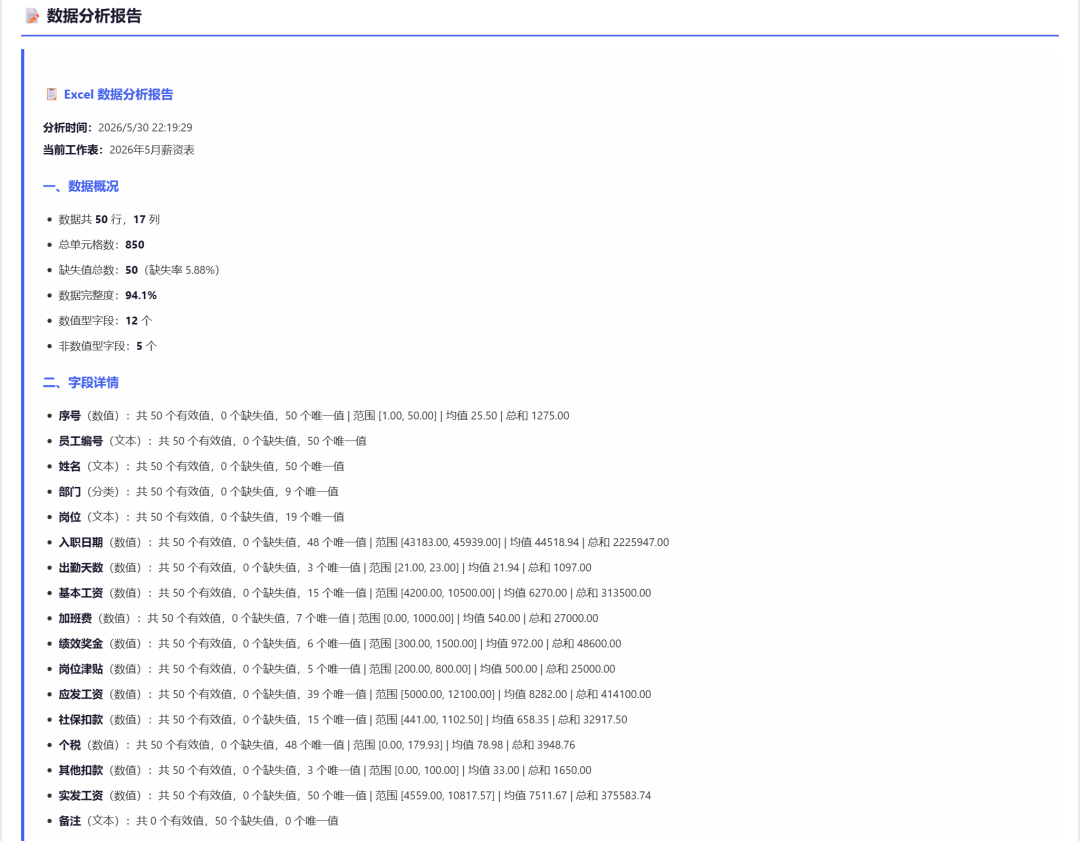
Here is the data-statistics preview:
Generated charts:
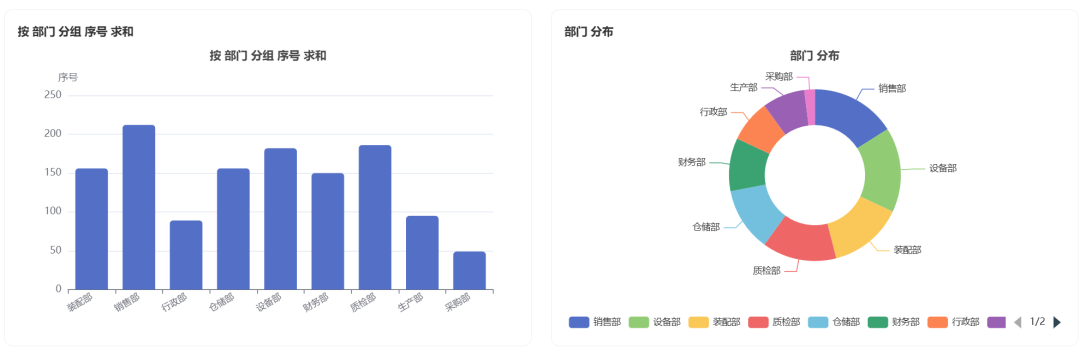
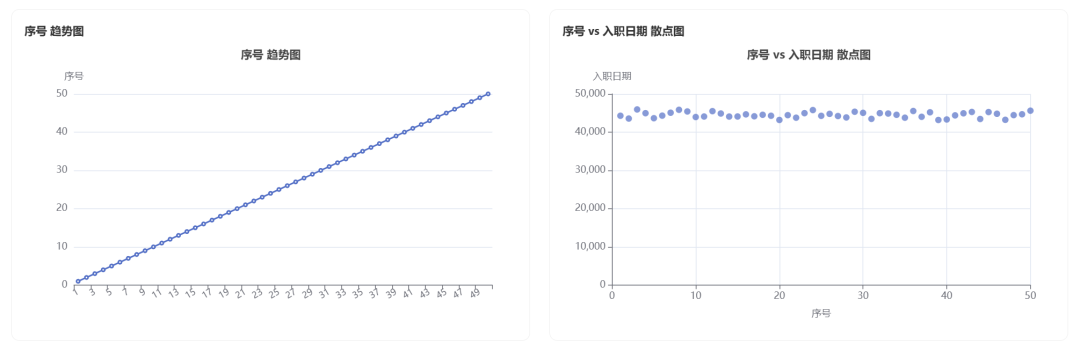
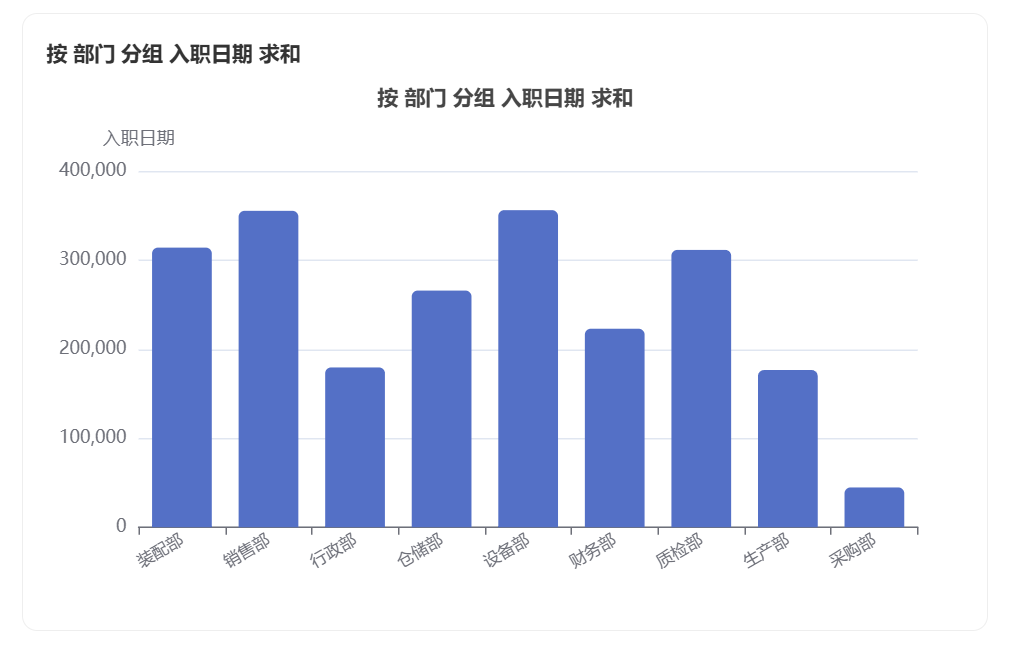
Part of the data report:
Then I sent the same task to Opus 4.8 and opened the generated HTML file:

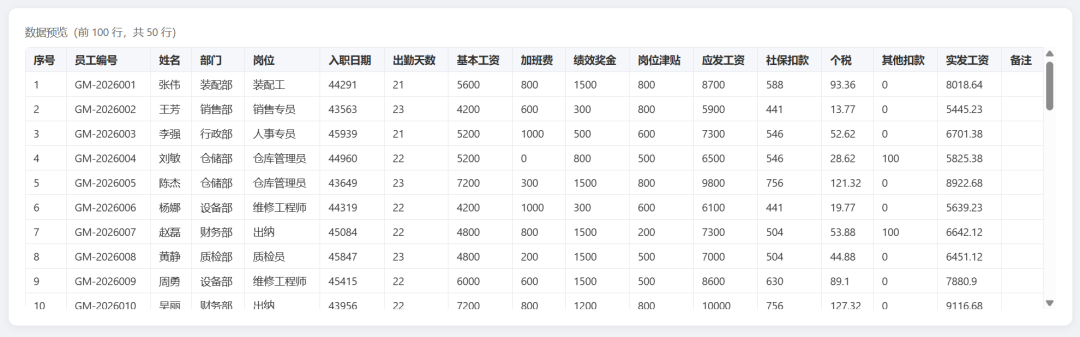
Data preview:
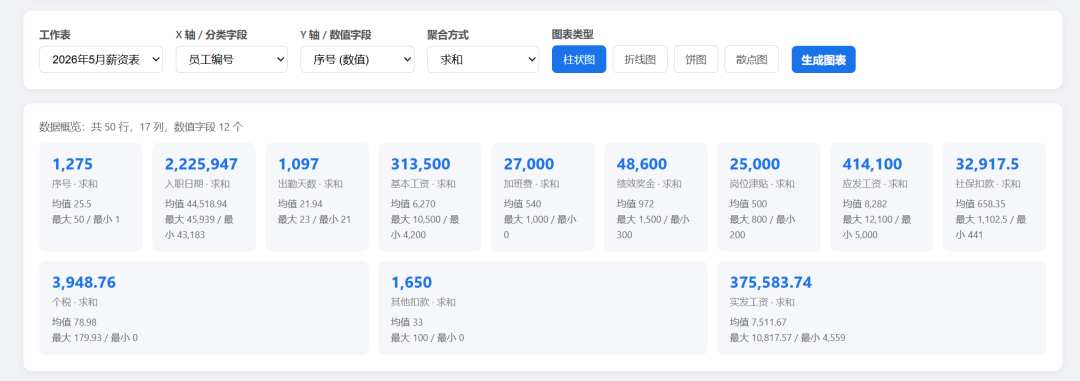
Data overview:
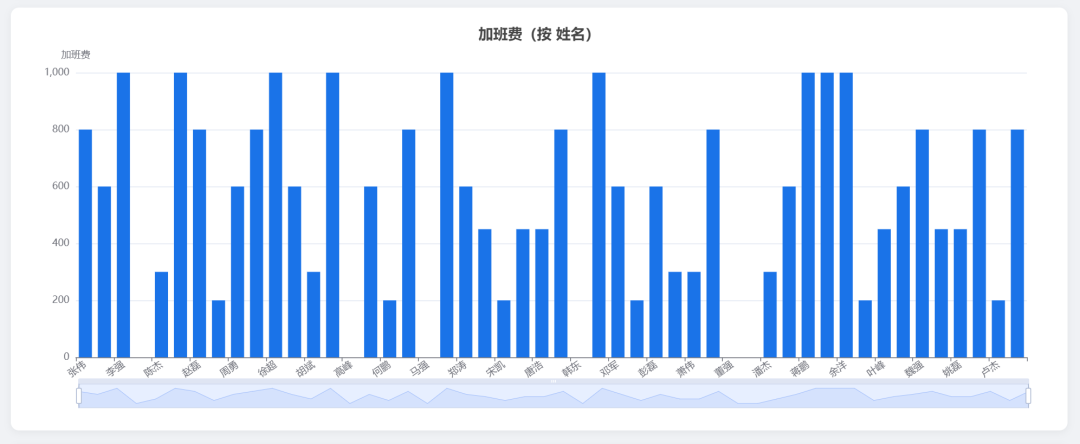
Bar chart:
Line chart:
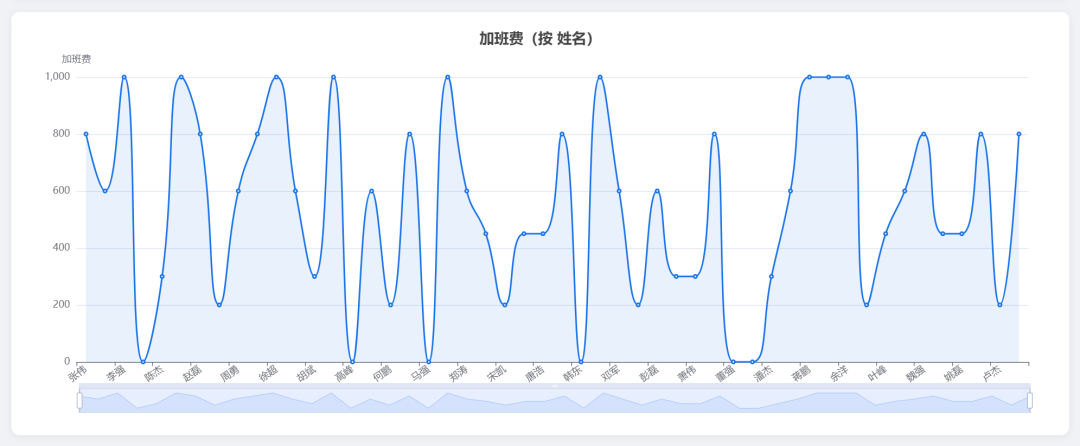
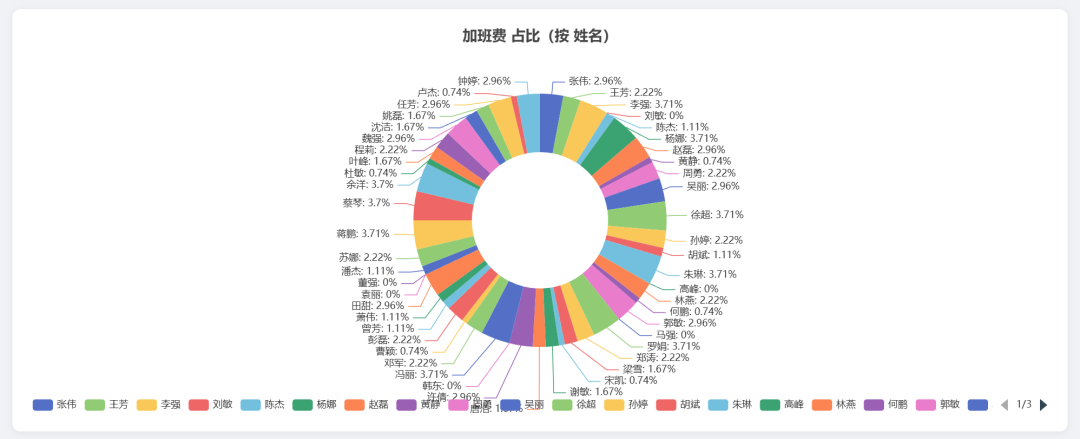
Pie chart:
I also sent the same task to DeepSeek-V4-Pro:

After opening the HTML file, the page looked like this:
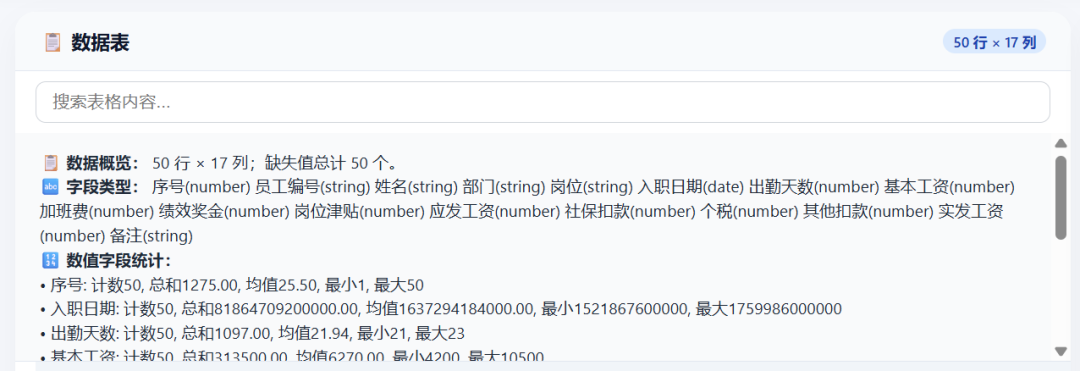
After loading the Excel file, it showed data preview, field types, and statistics:
Bar chart:
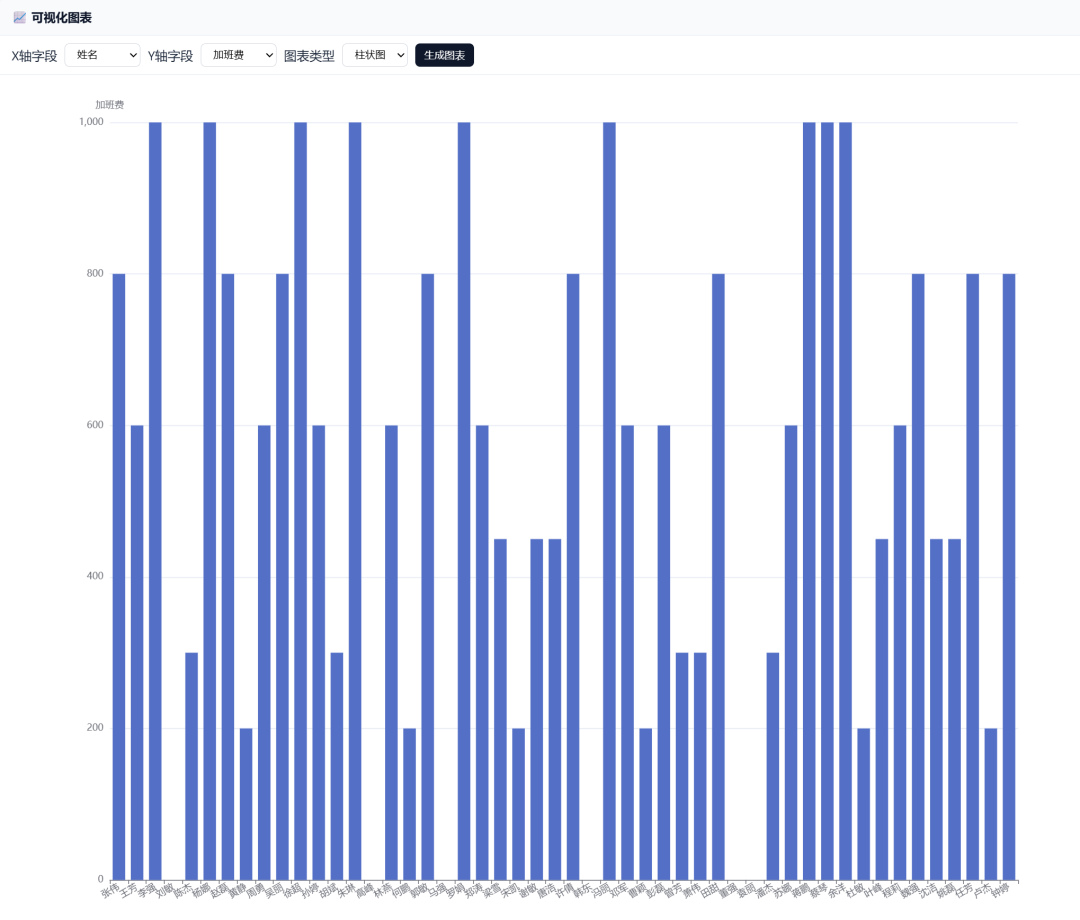
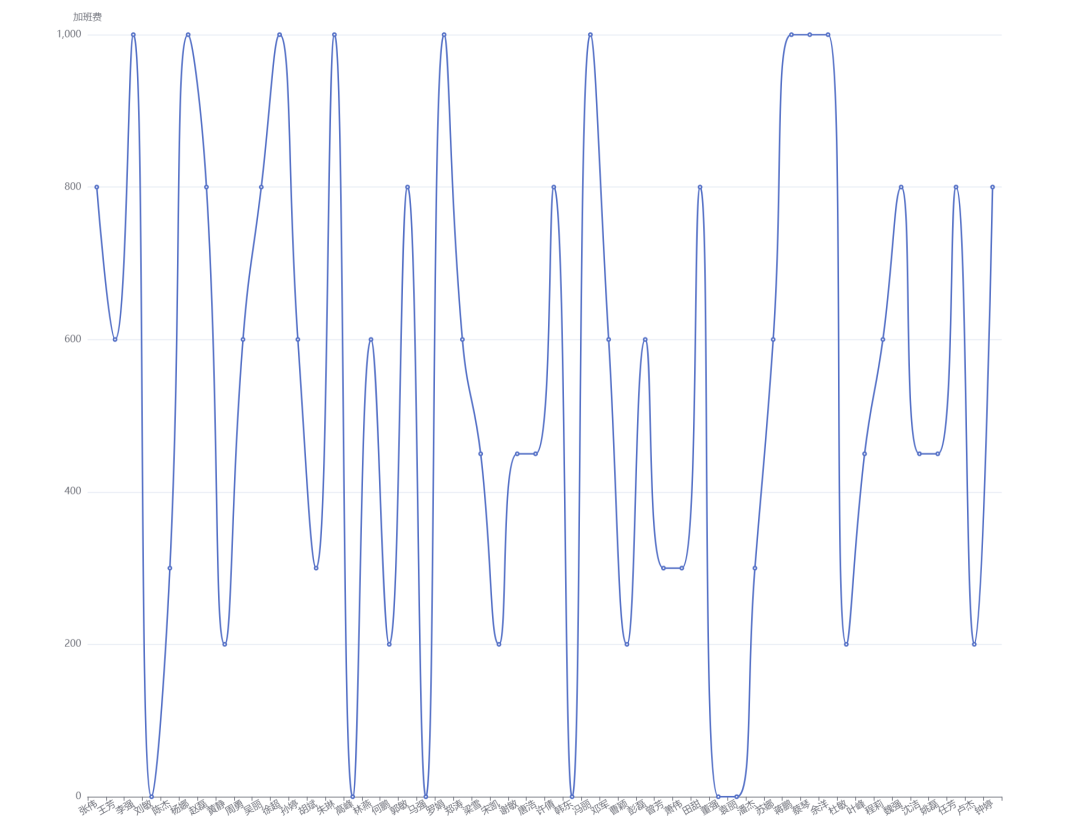
Line chart:
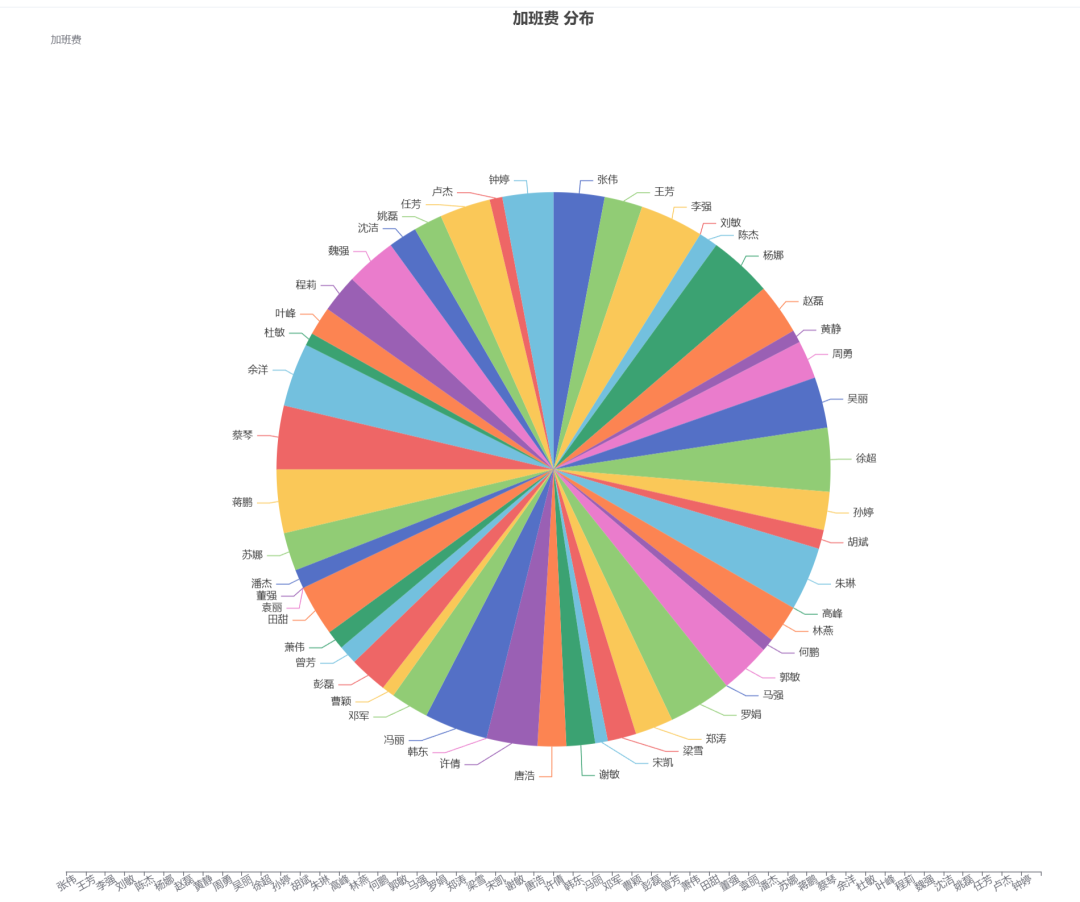
Pie chart:
3. Judge scores
To make the evaluation less subjective, I first asked Gemini-3.5-Flash to judge the three outputs:
These were the three scoring dimensions used by Gemini-3.5-Flash:
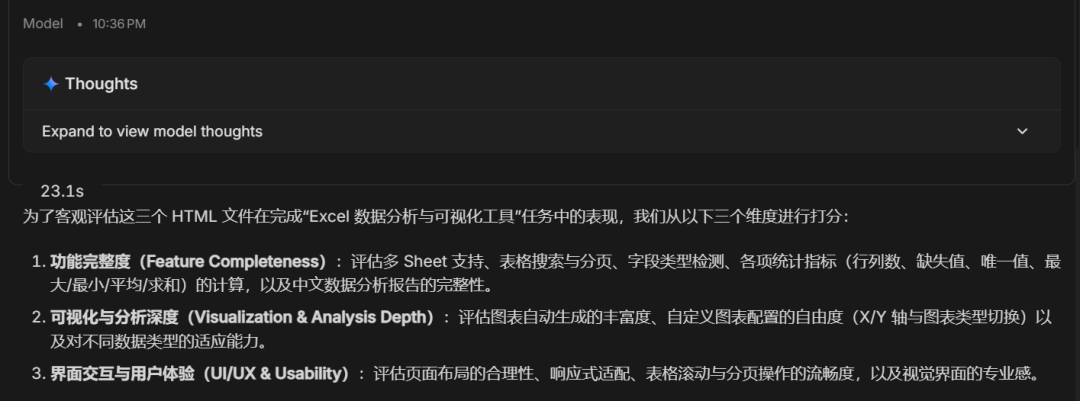
Final score:
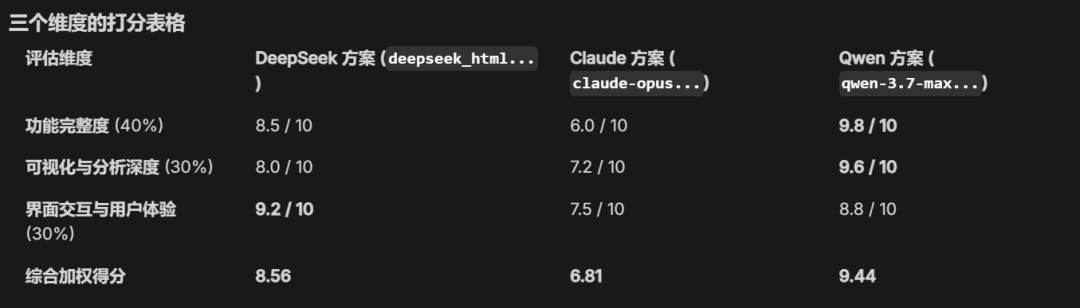
Claude Opus 4.8 scored only 6.8 and ranked last.
Qwen3.7-Max ranked first with a score of 9.44.
That surprised me. Based on the ranking at the beginning, Opus 4.8 should have been the strongest. In this test, it even scored below DeepSeek-V4-Pro.
Why did this happen? I asked the judge to explain:
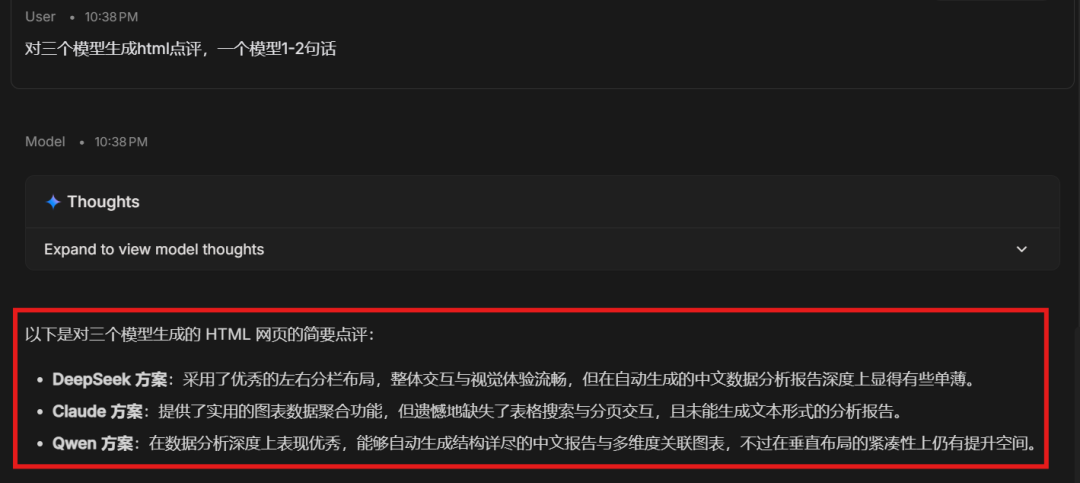
The DeepSeek solution used a strong two-column layout. The overall interaction and visual experience were smooth, but the automatically generated Chinese analysis report was somewhat shallow.
The Claude solution provided useful chart aggregation, but it missed table search and pagination, and it failed to generate a text-form analysis report.
The Qwen solution performed well on data-analysis depth. It generated a detailed Chinese report and multiple related charts, although the vertical layout still had room to become more compact.
In other words, Claude missed several important requirements and the completion level was weaker than expected.
This result was so unexpected that I wondered whether the judge itself was the problem. So I asked GPT-5.5 to judge the same outputs:
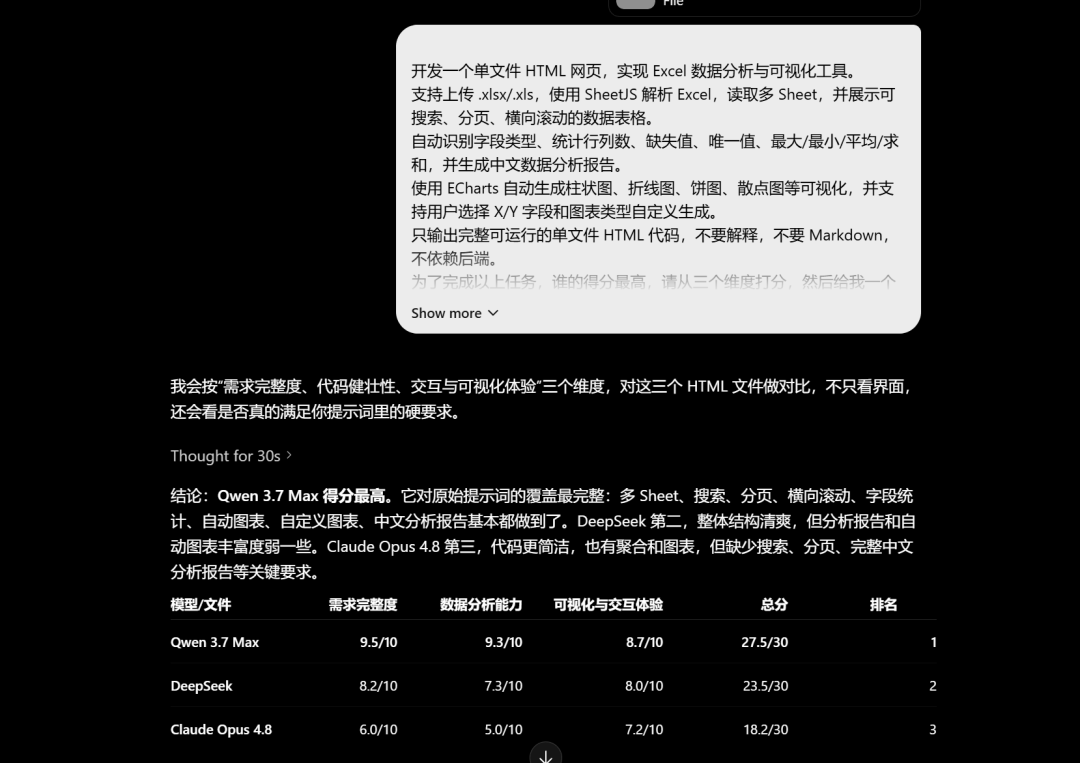
The ranking did not change: Qwen3.7-Max first, DeepSeek second, Claude Opus 4.8 third.
Here is GPT-5.5's detailed explanation:

At this point, the conclusion is clear: for this agent task, Opus 4.8 performed poorly.
Summary
Whether a model is good cannot be judged only by ranking, and definitely not only by brand reputation. The real question is how it performs in actual production tasks.
GPT-5.5 also described this task as a typical small-to-mid-size agent task:

For this specific agent task, Qwen3.7-Max ranked first, DeepSeek-V4-Pro ranked second, and Claude Opus 4.8 ranked third.
That was not what I expected. Of course, this is only one test, but it is still representative enough to be useful. I will try more complex agent tasks later.
This English edition preserves the screenshots and workflow order from the original Chinese article.